Konzept
Die (Neu-)Entwicklung von Pionlib begann im Herbst 2022 und erfolgt auf der Grundlage von RDA.
Das System bildet die RDA-Haupt-Entitäten ab und unterscheidet deshalb zwischen:
- Normdaten (inkl. Werke)
- Expressionen
- Manifestationen (inkl. Digitalisate)
- Items
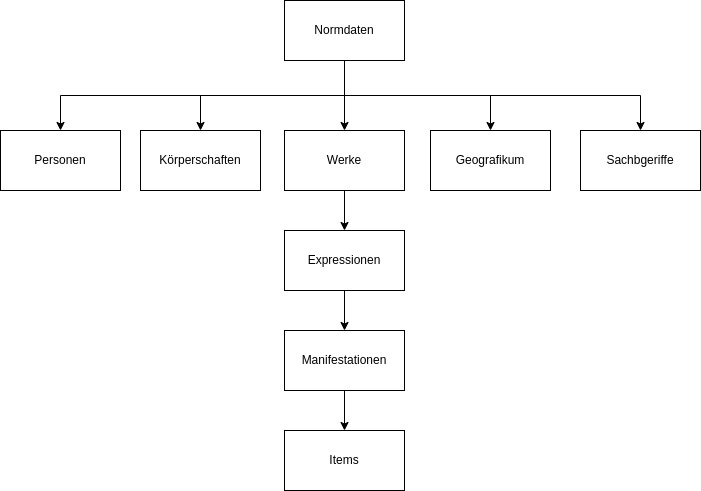
Personen, Sachbegriffe, Körperschaften, Geografika und Werke werden in Normdaten-Sätzen erfasst. (Wenn möglich, werden hierfür GND-Datensätze verwendet, die automatisiert aktuell gehalten werden.)
Mit den Werk-Sätzen werden wiederum Expressions-, Manifestations- und Item-Sätze verknüpft (WEMI-Modell).
Dieses Konzept folgt den RDA zugrunde liegenden bibliographischen Datenmodellen (FRBR, FRAD und FRSAD) und reduziert Datenredundanz auf ein Minimum.